一、前言
CDN 行业当中其实最有含量的重磅服务就是 CacheServer ,我有幸为公司面试过许多行业内的翘楚,比较遗憾的是做 CacheServer 这个组件的并没有多少。各大公司还是基于 Apache Traffic Server ATS 开源软件作为缓存的核心,用 C++ 为其开发插件来满足自身的业务需求。不能讲不能用,只是说许多公司用不好。
云端调度有时候会根据机器的负载、CPU、内存使用率来决定机器是否应该被调度。但是你不好决定 ATS 的内存占有率。很多时候 ATS 吃多了内存,系统内存使用率太高,云端调度就不给量了。亦或是 ATS 吃内存太多,人工介入太晚。导致服务被系统 OOM Killer。也不是稀罕的事情。
还有些问题就是 ATS 作为一款开源软件自身可能所携带的 Bug。 Bug 并不可怕,可怕的是市场环境没有那么多对于 ATS 熟悉的人。
这就好像你会用 Nginx 但是要你去改 Nginx 里的 Bug 你却无从下手的道理一样。更别提 ATS 这款几乎在 CDN 领域才会出现的软件。非垂直领域的人可能都没听过。
有幸和天翼云 CDN 专家聊过。他说 Nginx Proxy_cache 模块也不错。
确实不错 (后面我们接了字节的业务确实也用上了)。
但 Proxy_Cache 是基于文件系统的一套缓存服务,我们一位来自蓝汛的同事并不推荐,原因是他说因为 Linux 文件系统频繁擦写,Inode 可能会坏。 虽然我没遇到过,但是我听着还挺有道理。
此外 Proxy_Cache 属于 Nginx 上的模块。如果你接入层网关也是 Nginx 此时你又开启了 Proxy_Cache 。尴尬的事情来了,你无将缓存分片进行内网一致性 Hash 打散给集群内的它机器。除非你的 Proxy_Cache 是单独部署的,在 Nginx 接入层网关后面。就会造成 Nginx 套 Nginx 的尴尬局面。当然我这里说的 Nginx 一般都是 Openresty 。
领导是向来不想用 ATS 在大客户业务上进行跑量的。原因是因为我们在我们自有的其它业务上使用过 ATS ,确实会出现些奇奇怪怪的问题。虽然重启能解决,但是大客户要求的可用性 99.99999% 达不到。因为没有多余的人力去死磕 C++ 我们小组全是 Golang 的。
在去年我便自告奋勇的毅然决然的挑起了我要去搞 CacheServer 的这一面大旗。语言当然是我最熟悉的 Golang 当然也在业务上踩了无数的坑,我也用我的经历去考察了许多的面试候选人。只有实践后才能知道这背后的不易。写下这篇文章只为记录。
二、缓存架构
先说说我们的 CDN 架构。用户接入到 Openresty 后通过 http_slice_module 进行 HTTP Range 分片。通过 CacheKey 进行一致性Hash 打散到同机房下的缓存组件,最终通过回源组件回源。
简单图示如下:
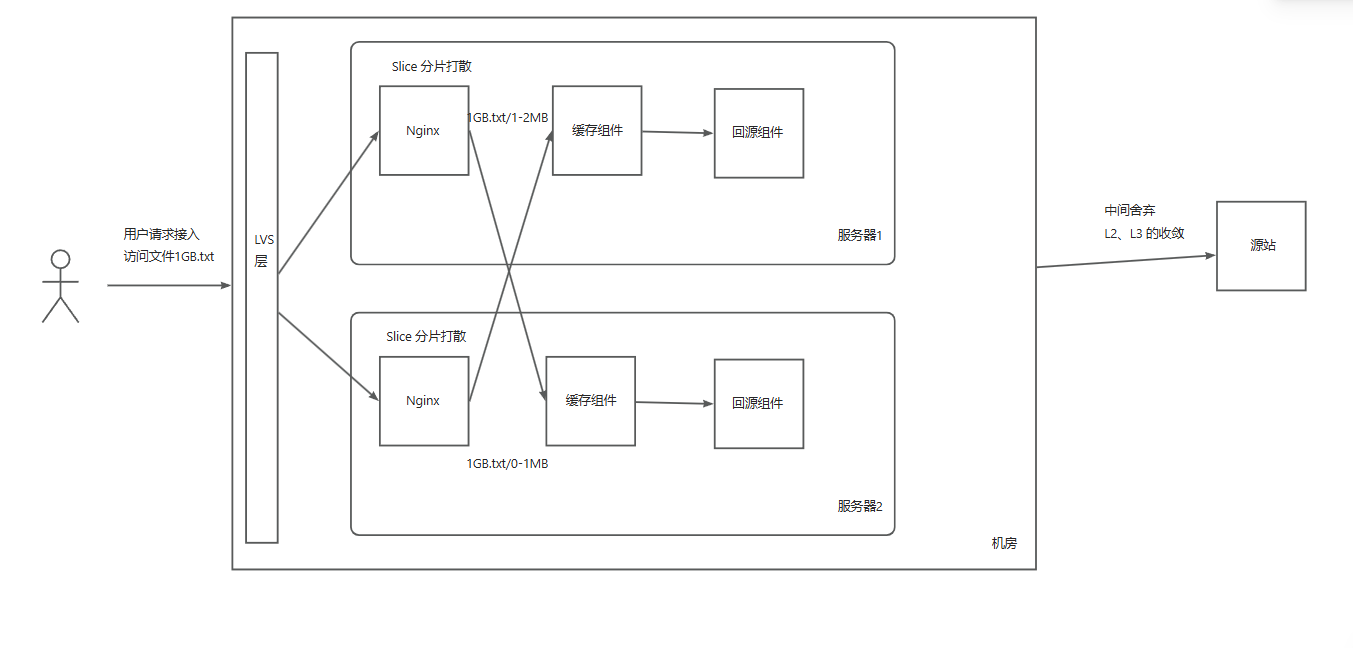
这几乎是业内 CDN 好多公司架构的标准,没什么说的。
(当然像网宿科技那种将 PCDN 节点跑在 L2 的这种精彩做法是值得一提的) 而上述架构就像面试中的八股文,不讲也罢。
而我的工作就是在实现图中的 缓存组件 。
三、硬件设备和跑量要求
缓存服务读写裸盘,支持以下几种场景
- 纯 NVME。双万兆网卡(内网通信网卡+公网通信网卡)/64核CPU/192G内存/3.84T NVME *4
- Bcache 模式。双万兆网卡/64核/192G/2*3.84T NVME/ 6T HDD *8
- 混盘模式。双万兆网卡/64核/192G/2*3.84T NVME/ 6T HDD *8 此处和 Bcache 不同的是 CacheServer 是直接对 SSD 和 HDD 进行操作。而不用再借助
Bcache根据磁盘性能,可自定义调控读写比例。
跑量要求单机公网网口 10 Gbps。
四、遇见的问题
1.磁盘读写放大和内网、回源放大问题
这个问题的名词是我自己定义的。
如果你的业务比较单一,就不会出现这种情况。这种情况主要是因为我的缓存分片是 1MB 也就意味着 Nginx 的 Slice 模块发送子请求单次 HTTP Range 请求的范围就是 1MB 。但遇到某些客户端软件采用 Range 0-256KB 的形式对你的 CDN 发起请求。这也就意味着,缓存服务向磁盘读取了 1MB 的数据,并且通过内网传输,吐给了 Nginx 。而 Nginx 只会给客户吐 256KB 的数据。这会导致有关联的所有环节都会将这个问题放大。 客户只要 256KB 但是你所有环节将这个影响放大了 4倍 。消耗了磁盘性能、软中断、网卡、甚至是回源、回父带宽。
很多时候我会发现,内网网卡 10G 都跑满了,但是公网出口网卡才跑了 2.5G 。亦或是上下行不对等的情况。排查了日志才发现是这个问题。
当然纯粹基于 Nginx Proxy_Cache 直接向用户提供服务,似乎就没有这个问题。因为缓存组件相当于直接来到了 Nginx 这个位置,直接给用户提供服务,能够直接拿到用户所想要的数据范围。
2.要命的垃圾回收问题
Go 是门优秀的语言。曾几何时,我一直认为做需求如果做不出来,只是因为这个人对这个语言的驾驭程度还不够深。直到我自己用 Go 写了 CDN 缓存服务。
缓存组件一般分为2层。磁盘缓存、内存加速缓存。用户访问一个数据一般都是要先去内存中查找,如果数据不存在则去磁盘中读取,然后再维护进内存。保证别的用户访问这块数据能直接从内存中高速分发。
缓存又都是一个又一个对象。我还得维护磁盘许多 Inode 。Golang 定时 GC 每两分钟扫描一次。这导致缓存服务本身就是缓存大量对象数据,被 GC 拖死。
我看了单机对象数可达到 3000W 甚至更多。其中一些是我磁盘的 Inode,还有一些是在内存中的缓存对象。 Go 的 GC 有时候就像个催命符。每两分钟一次。
我甚至关闭过 Golang 的自动 GC 并且全局采用对象池的手段,只有当我自己需要的时候才手动调用 runtime.GC() 但这依然很恐怖。 Go 的 GC 会对所有存在的对象都进行扫描标记。
这导致我在开发中不得不将一个大缓存服务拆分成多个子服务来降低单次 GC 导致的耗时。
从协程模型又退化成多进程模型。 这就像你开车用惯了自动挡,感觉自动挡很好,但当遇到性能问题,你还是会觉得自动挡换挡迟钝,不如手动挡来的快。
你驾驭不好自动 GC 的语言。除非你将 Golang 退化为全用数组而不用切片,使用 unsafe.pointer 的形式绕过 GC 。但这讲实话不如用 C 写,何苦用 Go
3.GC 问题导致的锁竞争问题
高性能软件一般要避免锁的竞争。很多面试题都问过 Golang Sync.Mutex 、runtime.Mutex 的实现。无非就考察用户态自旋、和 Linux Futex。
我已经经可能避免锁的竞争了。但是遇到高并发,并且缓存对象多的场景,触发了 GC 。过长的 GC 导致的 STW 过长。 锁从自旋变为饥饿模式。将用户态自旋锁升级为了 Linux Futex 当线程被唤醒后又造成了大面积线程的切换,CPU 异常的高。
4. nginx reuseport 、Nginx keepalive 、上游Go服务、Nginx worker 之间可能存在的问题
为了解决高并发 Nginx 惊群,我在 Nginx 上开启了 reuseport 功能。
开启后用户的请求会被均匀的调度到 nginx worker 上。
此时每个 Nginx Worker 的 CPU 都很均衡。
但是如果你设置了 nginx upstream 的 keepalive 与上游保活。那么恭喜你,如果数值设置的不好。上游的 Golang 服务 CPU 将会很损。 我采用了多方面去验证了这个问题。
为什么这么说?
你可以想象,有64个并发请求通过 Nginx 打进你的后端 Golang 服务,此时 Nginx Worker 也是 64 个。此时正好,nginx reuseport 生效,均匀的使得每一个 nginx worker 都与上游 Golang 建立了 TCP 连接。也就意味着 Go 服务瞬时会有 64 个 TCP 连接都保持了 Keepalive 。
请求结束后,由于 Golang 不会 Close 连接,一般采取 conn.Peek(1) 的操作进行等待下次的 HTTP 报文到来。我拿 Golang 开源的 fasthttp 框架来说。他就是下面这幅图
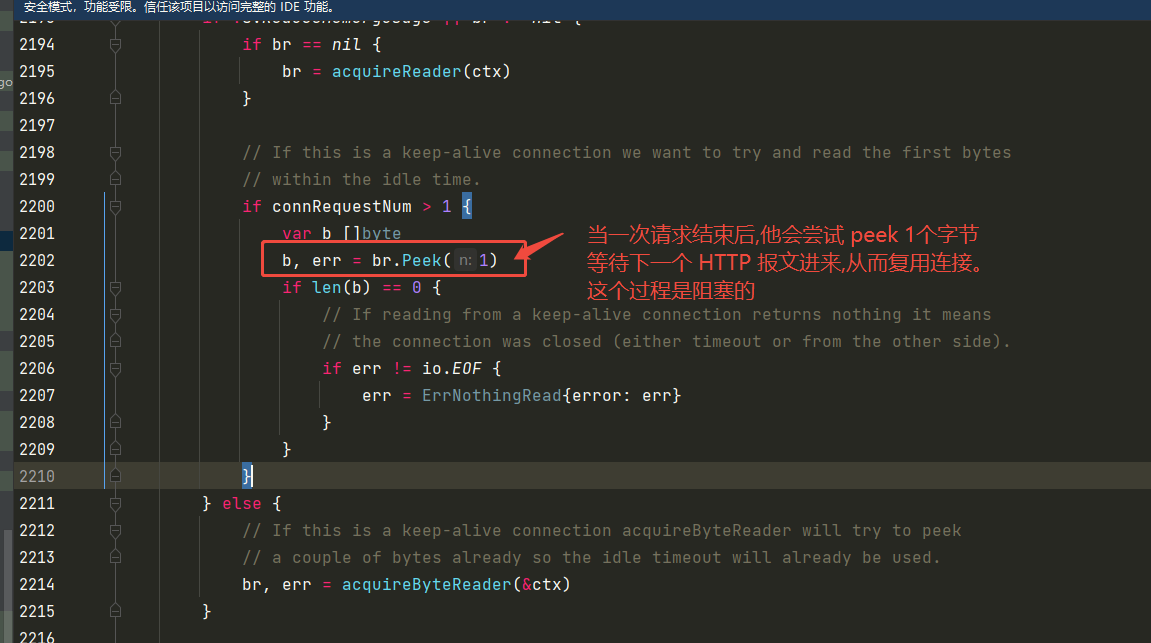
net.Conn peek 操作是一次阻塞性操作。 底层调用的是 syscall.Read 。当网络数据包还未到来,他会将 Go 协程 Gopark 挂起。请注意,这就是一次 Go Sched 调度。在 Go 调度的过程中 runtime 运行时会拿锁,这个锁是 runtime.Mutex,对应的就是系统级别的线程锁,而不是用户态锁。锁竞争频繁会触发 Linux Futex 将线程挂起。
可想而知,你预测你服务平日的 QPS 在某个恒定值下可以设置 Keepalive 的数量。这个数量不是无脑设置的,是要根据科学的依据来。太多了并不好。
你超过了某个恒定的值,导致 Golang 本身不需要这么多 Keepalive 连接,但是你还强行设定了这么多连接。
当单位时间内并发请求一瞬间到来,所有的 Go 协程都会因为这个 peek 操作而被 GoPark 。少说这一瞬间少说是几百个 Goroutine 的协程切换。
瞬时的并发,其实他完全可以不用那么多 Keepalive 。
四、如何解决上述问题?
1.拆进程
拆进程,缓存服务将一个进程拆成多个。就像 Nginx 有多个 worker 一样。每个进程管理部分缓存对象,避免单次 GC 过长的 STW 导致系统抖动。
2.全局对象池
全局采用对象池,尽可能做到所有对象均复用,不要让 Golang 的 GC 提前到来。
如果你有实力,可以让 Go 在一定的 QPS 下不额外分配内存,甚至不额外创建对象。再把 Go 的 GC 关闭,这就完美了。
但实际落地这不太可能,因为你还引用了 Golang 的标准库甚至是第三方库。但凡一处不符合你心意,上述的理想情况均被打破。
3.多看标准库的实现
标准库有些不期望的地方。导致我在写缓存服务的时候生怕调用了一个标准库的方法,底层以一个 make 切片的地方。因为这意味着都是在给我创建内存。我担心 GC 的提前到来,本来单次 GC 全局扫描已经够痛苦了,如果这个痛苦还频繁提前,就不用玩了。
至此我煎熬的熬过了缓存服务实现的全过程。
4.读写放大问题的处理
Slice 分片要根据业务特性决定大小。部分业务方的点播业务 Range 范围 256K,如果 Slice 1MB 分片。所有数据传输都会放大。除非把 CacheServer 整合进 Nginx 这一层
兰陵美酒郁金香
大道至简 Simplicity is the ultimate form of sophistication.
文章评论(0)