一、前言
看了 Dog250 大佬的文章,才有感记录下这个心得。
毕竟目前我就是干 CDN 加速这行的。
CDN 领域中,主要分为动态加速分发和静态加速分发两种。
静态加速从狭义简单的来讲,就是用来加速分发 js、css、html、音视频、直播流等不会变更的资源。
动态加速讲白了可以理解为加速 HTTP 后端动态接口,如何优化网络链路,让一个后端数据接口更快响应。
两种在分发的侧重点不同,用形象的比喻我把它称为笑傲江湖中,华山派的 "剑宗"和"气宗",两个分支。
"剑宗" 静态内容分发 旨在控制良好的短距离传输,侧重在静态内容距离用户的最后一公里。
"气宗" 动态内容分发 旨在控制良好的短距离传输控制 侧重在从第一段到最后一段的所有环节的流水线配合。
而我们业务平日接触到最多的是静态内容分发。即在距离用户最近的地理位置的地点部署缓存机房。而疏忽了"气宗"的重要性。(注:为什么疏忽??? 用领导的话术来讲就是动态加速不赚钱)。
而本次的话题,我们围绕制造一个跨境传输的场景来讲讲其中都会涉及到的问题,并试着给出解决方案。
二、场景假设
假设1:我的家就在 IDC 机房,出入口带宽 1Gbps,上下行对等。我要玩一款美服的游戏,在玩的过程中如果我们不介入加速器的帮助,为什么还会这么卡,延迟波动这么高?
假设2:我的家在 IDC 机房,出入口带宽 1Gbps,上下行对等。我要下载美国服务器上的一个文件。抛除美服的带宽因素(假设也是G口),为什么我单线程下载速度总是跑不满?
三、思考分析
细品网游加速器和科学上网软件都是怎么做的,以及他们为什么要这么做?
- 科学上网为什么需要跳板?例如入口上海 BGP节点、出口美国洛杉矶节点? 为什么不能直接做直连?还非得经过上海?
- 部分价格高的加速器厂商会租赁 IPLC 专线。
- 为什么大部分科学上网都会升级Linux内核并开启 BBR 加速。
四、原因解析
1. 出境网络质量与运营商的关系
不同运营商出境走的线路是不同的,详见: https://blog.zekun.fun/2024/%E6%96%87%E6%A1%A3%E6%95%99%E7%A8%8B/%E3%80%90%E8%BD%AC%E3%80%91%E7%A7%91%E6%99%AE%E5%90%84%E4%B8%AA%E5%87%BA%E6%B5%B7%E7%BA%BF%E8%B7%AF/
此处大体你可以理解为要均衡用户所在家庭宽带运营商的差异。家庭宽带三大运营商不一定每一个出境效果都好。
而国内接入 BGP 线路就是为了屏蔽这一差异。
2. 基于 Reno 丢包检测的拥塞控制算法 Cubic (慢启动)
Linux 默认采用 Cubic 这种对丢包敏感的拥塞控制算法。TCP 都有一个慢启动的过程, 在慢启动阶段与 Reno 类似,即每收到一个 ACK,cwnd 指数增长拥塞窗口(cwnd) 翻倍。直到 cwnd 达到 慢启动阈(ssthresh),进入拥塞避免阶段,变为线性增长。直到检测到 丢包(loss), 认为网络发生了拥塞,大幅度减少滑动窗口的大小。一段时间后,重新回到 slow start 的状态。
整体流程如下所示
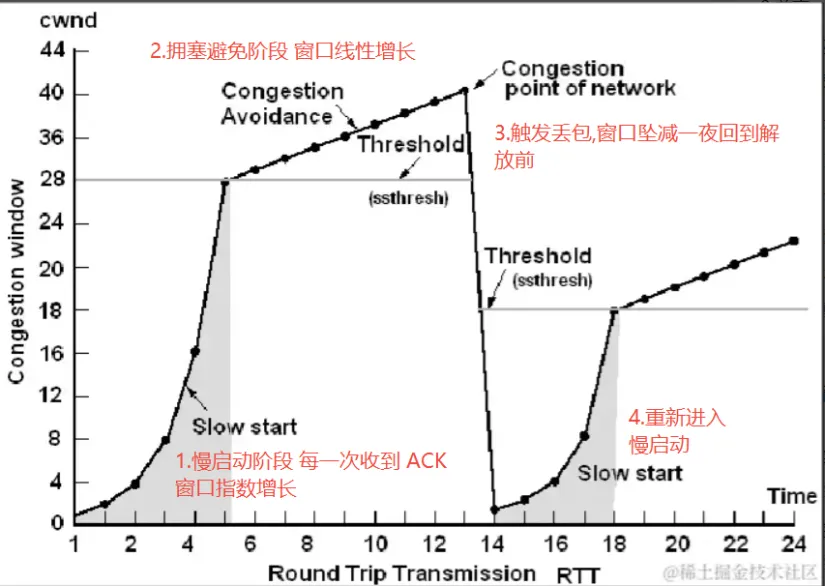
而跨境链路传输中,物理链路越长,数据包往返的 RTT 耗时也越大,收到的 ACK 时间越大, 因此窗口开放的也越慢,慢启动阶段耗时非常久。由于物理链路复杂,假设慢启动在第 10s 时发生了丢包。 然而一旦检测到丢包,将会执行MD,即陡降的过程,这是一个快速降窗的过程,几十秒的努力,一秒不到就回到了解放前。
3. 网络设备 BufferBloat 问题导致的丢包反馈延迟
受到 "摩尔定律" 的影响,硬件性能提升。大多数厂家出售的网络设备 "路由器" 的 Buffer 越来越大。这个就像人们拼命比拼谁的电脑内存大一样,因为在一般人眼里,内存越大就越快!然而对于网络而言,恰好相反,内存越大,越让人不想归家。
首先先解释下什么是 BufferBloat 。如下图
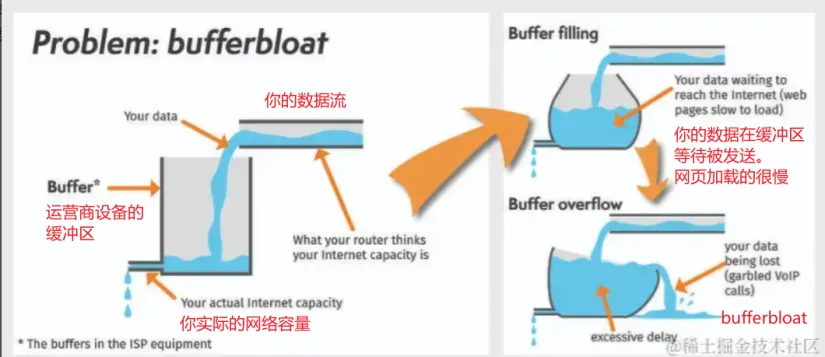
从图中我们能看到,当我们的发送数据和网络实际容量相等时,带宽的利用率是最高的。
当发送速度 > 实际网络容量时,设备缓冲区上开始有数据积压,这也就是我们常说的拥塞,但此时未必会发生丢包。
因此第一个结论即: 拥塞不等于丢包
但是设备缓冲区积压已经意味着你的报文可能还未从设备缓冲区中发出。
对于用户而言,此时数据包往返时长 RTT 开始增加,网页加载开始变慢。
但 Cubic 拥塞控制算法不会因为 RTT 变长就开始收敛,它是一种基于丢包的拥塞控制。
由于中间网络设备不会主动反馈用户设备,如果用户的应用程序还是在不断的发送数据报文,最差的结果就是缓冲区溢出,产生丢包。用户设备的内核协议栈感知丢包,收敛窗口,又进行重新的一轮慢启动,窗口放大周期又是根据 ACK 次数,又原因是跨境链路传输,带宽发生频繁震荡。
4.长肥管道对网络传输的影响
1. 长肥管道的概念
瓶颈链路的概念很重要
瓶颈链路(Bottleneck Link),管道最细处决定了最大速率,同时也是数据堆积的地方
我们还是可以抽象的将我们的 TCP 流看成一根水管。水管的容量也就是我说的主角: BDP 带宽延迟积(Bandwidth Delay Product)
表示的意思就是某一时刻的网络中仍在传输中的最大数据量。当然这里要注意的是,路由器等网络设备中的 Buffer 数据除外。这个水管内的数据又被称为 Inlfight(飞行中的) ,意思为未到达目的地的数据。

它的计算公式是
BDP(带宽延迟积)= RTT (往返时延。即图中的 Delay) × BtlBW (瓶颈带宽 全称 bottleneck bandwidth。即图中的横截面)
而这根管道也就是也就是标题中所说的"长肥管道" 最理想的情况就是要让管道内充满源源不断的数据。而路由器等网络设备又不会出现 Buffer 积压的情况。
2. 长肥管道影响对 TCP 传输的影响
2.1. 对内核缓冲区的影响
TCP 每次发包都有确认机制,并且 Linux 内核有 TCP 发送缓冲区和接受缓冲区。由于 "长肥管道" 的存在,管道越长,意味着每次数据包往返确认的 RTT 越长。
因为TCP数据包在未被确认之前,是不能删除的,它们在发送出去后将继续占用发送缓冲区,只有被确认后才会被清除,而被确认的时间则就是RTT,因此,RTT越小,一窗口数据就越快被清除,从而腾出发送缓冲区,继续发送下一批次的数据!
长肥管道更容易使发送缓冲区耗尽,且清空时间随着RTT的增加而增加,从而影响单流的传输速率。
我预期,如果RTT超过一个阈值,即链路长到一定的程度,现有的TCP将完全不可用! 因为你要保证不能丢包,不能重传,更不能超时,一个都不许有…这是相当难的!
2.2. 接收端通告窗口消息发送的滞后性
- TCP 反馈延迟增加:由于 RTT 长,接收方调整 rwnd 的反馈到达发送方的时间变长,导致窗口调整滞后。接收端此刻发送给发送方的通告窗口是小的,这不意味着经过长时间的传输后到达发送者的手中,接收端依旧是小的。如果接收方处理速度快,但 rwnd 增长 RTT 滞后,发送方可能无法立即利用可用带宽
五、如何解决上述问题并实现动态加速?
1. 如何处理 bufferbloat 对网络造成的影响?
通过上图我们知道, bufferbloat 造成的影响是丢包感知延长。基于 cubic 这种拥塞控制算法由于感知丢包滞后,还是不断的发包,直到中间网络设备的 buffer 塞满,事态变得不断加重。
聪明的小伙伴经过思考想的是 buffer 变小,更容易将 buffer 塞满,更容易触发缓冲区溢出,也还是会出现丢包,好像这个问题就无解了。
buffer 大小就像生活就像炒菜的食盐,你加少了味淡,加多了齁咸。控制恰到好处的量才能实现食物最大的价值。
实际上,拥塞控制算法的意义就在于能及时敏感的感知网络状况。 buffer 太大,丢包感知滞后,拥塞控制算法不能精准感知。
路由器 Buffer 小的好处在于,即使有连接拼命去添堵,那么丢包会很快到来,并且很快反馈给发送方,于是发送方会执行MD (Multiplicative Decrease)降低窗口的过程 以表示忏悔,整个过程中,实时流量不会受到丝毫影响。
当然你无法修改运营商的网络中间层设备,因此你只能替换拥塞控制算法。即 BBR基于 RTT 往返时长计算拥塞的控制算法,而不是纯基于丢包的算法。
2. 如何处理慢启动实现高吞吐
无论今天使用的是 Cubic 、BBR 均无法逃避慢启动问题。只不过二者窗口开放的速率计算不一样。
但二者计算核心都离不开 RTT这一指标。 地理位置远了、跨运营商了,自然 RTT大了。客户端窗口开放自然就慢了。
而你无法决定客户端的发送窗口,正如你无法决定客户端的拥塞控制算法。
一款不适用的算法在慢启动探测还未结束,可能业务流程就已经结束了。
正如我作为客户端当前要调用一个海外的 /api/userinfo 接口。接口从发送到响应,甚至可以讲慢启动还没结束。
但现代软件都是有 HTTP Keepalive 的。它会复用链接,发起下一个请求。但又如何?
下一个请求可能还是在慢启动中。加上跨境数据包不稳定,一个丢包打回原形。
怎么解决?
借用大佬 dog250 的一张图。引入 TCP 中继 的方法。
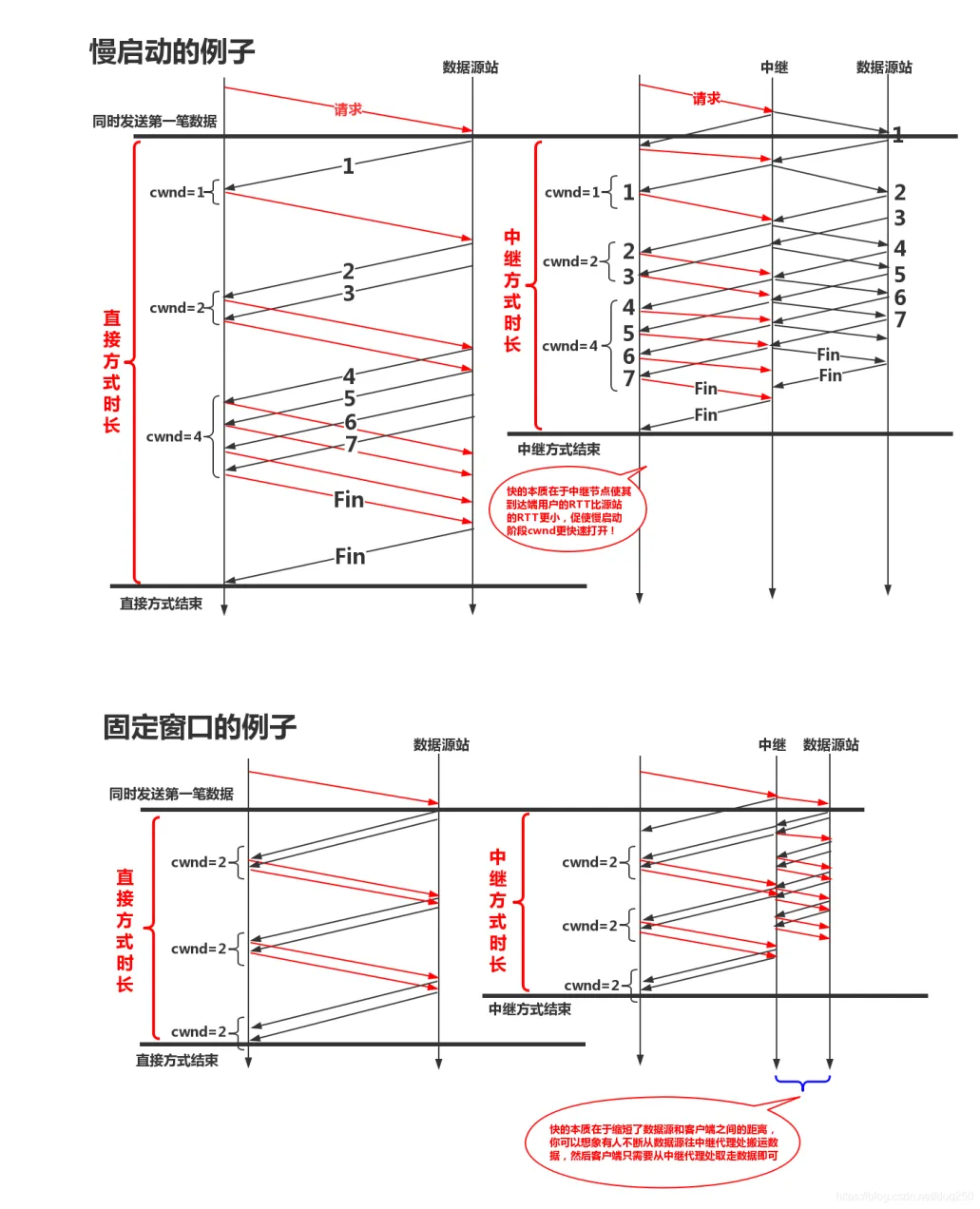
TCP时延 = 传播时延(RTT) + 排队时延(运营商 snd Buffer 的时延) + 处理时延(内核协议栈的处理时延)
但是和传播时延相比,处理时延可以忽略!
因此在增加了TCP中继代理之后,虽然增加了单个数据包的处理时延,但是由于流水线操作对传播时延的优化,这样做依然是值得的!上图中仅仅以两个流水线级作为例子,流水线级数,即TCP中继代理越多,吞吐就会越高。
至于说为了流水线可以提高吞吐,我想了解CPU流水线处理的都应该明白吧。其本质就是 让系统的不同组成部分可以同时处理一件事情的不同阶段, 这样整个系统便没有空闲的部件,所有都在忙,当然效能最高!效能我们可以理解为吞吐。
TCP在设计的时候,就是一个流水线协议。我们从最简单的 停/等协议 说起。停等协议的时序图是下面这样的:
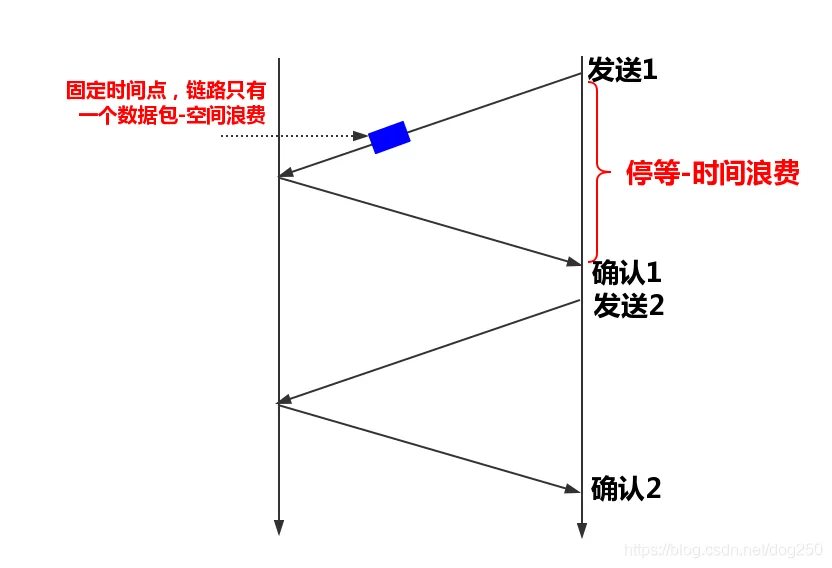
我们可以看到,这是一个典型的单程操作,在一个数据包的ACK未返回期间,链路是静默的,显然这在吞吐效率上是非常低的。整个RTT只能传输一个数据包,时间和空间均造成了巨大的浪费。
TCP的设计者当然不会采用这种方式来设计协议。
为了避免时间(数据包传输的时间)和空间(数据包在单位时间内通过的距离)的静默浪费,可以把时间和空间切割成背靠背的小段,流水线的意思是说前面一秒发出一个数据包到达前面一个位置,那么后面一秒就可以发出另一个数据包占据前面数据包后面的位置。 最终效果就是,在端到端数据传输路径上,每一个位置都有数据包在向前传输,它们在时间轴上依次向前推进:
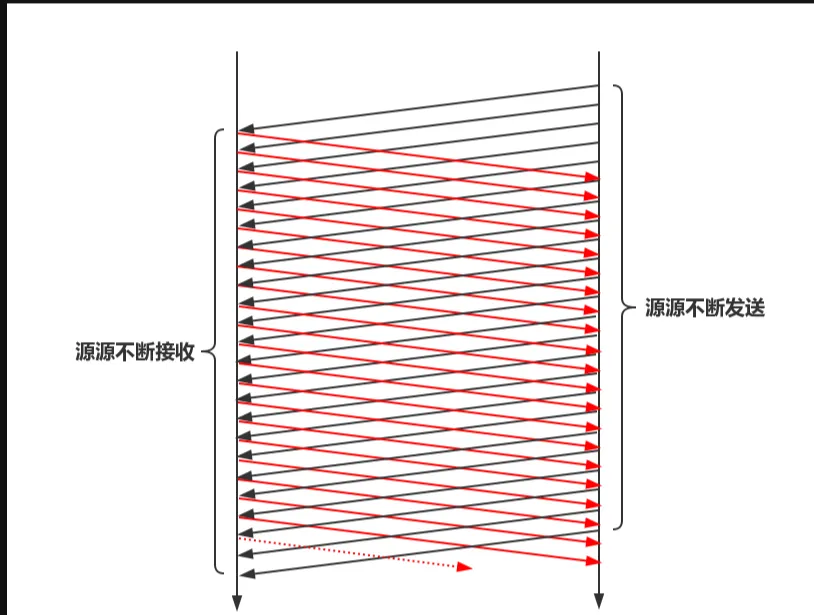
从理论上看来,TCP本来就被设计成了流水线协议,既然它本来就是流水线的,再基于同样的思想引入TCP中继,造同样效果的流水线,当然是无济于事了。
但真的是这样吗?理论上是一回事,现状是另一回事。在现实中,TCP从来没有按照理想中的流水线方式工作过。也就是说,TCP真正跑起来时其行为并不像理论上的推论所描述的那般。因此,流水线当然不能好好的工作了。
我们来看看是哪里出现的问题。理论上TCP数据包是以相同的时间间隔发送的,而现实中,在BBR之前,大多数的TCP实现均是以主机延时在一个while循环中把一窗口的数据包突发出去的。我们将其归为Burst(突发)行为。
- Burst行为
- 慢启动(Slow Start):TCP 连接建立后,初始拥塞窗口(cwnd)较小,但随着 ACK 的返回,窗口指数级增长,可能导致数据包突发发送。
- ACK 聚合(ACK Aggregation):如果接收端的 ACK 由于网络延迟或批量处理而积累,发送端可能会在收到多个 ACK 后一次性发送大量数据包。
- 定时器触发(Timer-based Transmission):某些 TCP 机制(如 RTO 触发的重传)可能导致数据包在特定时间点集中发送。
- 应用层行为:某些应用程序可能会在短时间内生成大量数据,导致 TCP 发送突发流量。
突发行为可能会导致 网络拥塞、丢包增加、队列积压,从而影响 TCP 连接的稳定性和吞吐量。
其次,由于上的Burst行为,中间节点的排队将会加剧,于是产生了大量AQM算法,产生了 TCP 发送端和 AQM 之间的博弈。
此后的TCP传输的难题就是 能发送多少数据 的难题,即计算拥塞控制窗口cwnd的难题。
网络传输行为是一个动态的行为,这意味着cwnd是无法准确预估的,我们归纳为:cwnd测不准
最终,TCP传输的流水线特征就不可能呈现了。我们知道,在TCP中,由于带宽的无法预估,初始cwnd不得不从一个非常小的值开始试探,而慢启动期间cwnd增长的速度和RTT是相关的,所以就为增加TCP中继代理提供了优化的空间。
说了这么多流水线以及TCP的历史上的一些的事情,其实这是在为TCP中继代理为什么能提高系统吞吐率作一个理论上的保证。有了这个理论上的保证或者说依据,我们就可以采用多级代理的方式来重构TCP连接了。这其中有很多值得深思的好玩的东西。
采用中继会减少排队和丢包
我们知道TCP是端到端协议,其对中间链路是无感知的,拥塞控制机制中的cwnd如何能相对精确预知,一直是一个世界级难题。可以肯定的是,TCP两端相距越远,RTT越大,链路状况越是难以获取,误判越是会增多,而误判的后果就是排队或者丢包。
采用TCP中继代理后,原本长距离的链路被切分成了多个段, 每一个小段的可控性会更高些,且RTT的减少本身就会提高吞吐。我们关注下面两点即可:
越短的链路越不容易丢包,越不容易拥塞,RTT越小超时带来的cwnd陡降的影响越容易恢复。
可以针对每一个小段进行定向优化,比如提高初始cwnd等。
采用中继可以让选路策略更加灵活。这个无需多说,TCP/IP协议栈越往上层走,可以利用的策略就越丰富,见下图:


3. 自研协议
我一向不推崇在 L1 到 L2 之间采用 KCP 等暴力的加速协议,也不建议使用 Quic。首先UDP 被运营商 Kill 一直都是不争的事实,此外 Quic 本身也不是为加速而生的。
但 L1 和 L2 之间的传输还是可以进行多路复用、报文压缩的。但我不建议使用 HTTP2 ,虽然 HTTP2 有多路复用,但它强制性依赖于 TLS 。
你知道的 TLS 握手也是一个讨厌的阶段.加密与解密也很耗时,加速场景下需要压缩而不是加密。
我观察过业务数据流量,如果源站返回的数据流是音视频,则它就没有太大的压缩空间。因为音视频编码本身已经压缩过了,还要再二次进行压缩,耗时且费力,最重要是不讨好,因为基本没什么空间可压缩了,但 HTTP 报文头还是值得去压缩。
HTTP 报文头还有 Content-Type 字段,它能指导我在 L1 和 L2 之间是否执压缩。很明显响应头的 Content-Type:application/javascript 是我值得为其压缩报文体的。
但 Content-Type:application/octet-stream 就算球了。
还有些 TCP 多隧道的方案形式。其讲白了就是将原本的一条 TCP 流,切分到多个 TCP 流中。减少单流拥塞窗口变化造成的全局性影响,将这种变化平摊到多个流上。
4. 专线
典型的就是阿里云,它的私有 VPC 私有网络可以支持跨地域,直白的理解,这也是云厂商自己内部的骨干网了。
阿里云有款产品就叫全站加速,我试想有实力的厂商无需考虑那么多问题,VPC 链路链接国内各大一线城市。
网络数据包在跨省通行时无需走三大运营商的骨干网,内部就能自行消化,那么上述所说的网络问题,在这种土豪行为下,显得更像是马保国的闪电五连鞭。
更别提跨境场景下, IPLC 专线这种行为,当然讲白了还是钱的问题。
参考文章:
https://blog.csdn.net/dog250/article/details/54999332
https://www.cnblogs.com/buttercup/p/13812221.html
兰陵美酒郁金香
大道至简 Simplicity is the ultimate form of sophistication.
文章评论(0)